Understand why and how to use Google hosted Apache Beam service for your data pipelines.
Davi Kawasaki
9 min read

Data pipelines have become increasingly important in the modern era of big data. As organizations generate and collect vast amounts of data, they need efficient and reliable ways to process, transform, and store that data. Data pipelines provide a way to automate the process of moving data from one system to another and processing it as it flows through the pipeline.
One example of the importance of data pipelines is in the field of data warehousing. Data warehousing involves collecting data from various sources and processing it to create a central repository of information. Data pipelines play a critical role in this process by allowing organizations to move data from various sources into a centralized data warehouse, such as AWS Redshift and Google BigQuery.
Another example is in the field of machine learning. Machine learning algorithms require large amounts of data to train and improve their accuracy. Data pipelines can be used to automate the process of collecting and processing enough data for machine learning models.
Overall, data pipelines have emerged as a crucial tool for organizations that need to manage and process large amounts of data efficiently, faster and reliably. By automating the process of moving and processing data, data pipelines enable organizations to focus on analyzing and extracting insights from their data, rather than spending time on manual data management tasks.
The first generation of tools for data pipelines were often custom-built solutions that were specific to individual organizations, normally focused on ETL (extract, transform and load) processes. These tools were typically designed to run on-premises and required significant investments in hardware and software infrastructure to make sure deliveries were fast and reliable.
The second generation of tools for data pipelines were focused on providing more flexibility and scalability. These tools were somewhat cloud-based (sometimes as an offered service or needed to run on VMs) and offered features such as automatic scaling and resource management. Examples of tools in this generation include Apache Airflow, Apache Hadoop and Apache NiFi.
The current generation of tools for data pipelines are designed to be even more scalable, flexible, easier to use and automated. These tools are often based on containerization technologies, normally focused on hosted services or serverless underlying infrastructure - this means they can be deployed across multiple cloud providers or on-premises environments. Examples of tools in this generation include Apache Spark (AWS Glue and Google Dataproc) and Apache Beam (Google Dataflow).
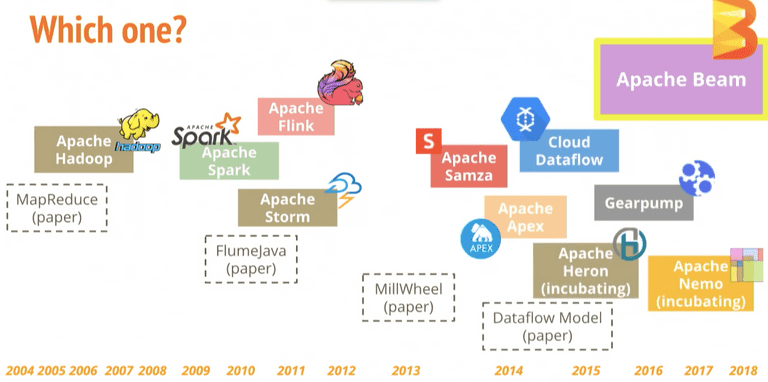
Google Dataflow is a cloud-based data processing service that allows users to build and execute data processing pipelines through a NoOps model - Google handles resource allocation, lifecycle, optimization and even rebalancing. Dataflow is built on top of Apache Beam, which is an open-source unified programming model for both batch and streaming modes, all supported by common programming languages such as Java, Python and Golang.
Its model provides higher level modules that abstract low level distributed and parallel processes in a portable way - enable developers to have one single code that can run across different runtime engines. Aside from that, its unified model allows the integration of batch and streaming, meaning that one can have the same model interchange between these two big data paradigms.
In either one of these two paradigms, there is a need to understand how data will flow through using the following main core concepts:
ParDo, GroupByKey)
The following list has some common transform types:
TextIO.Read and Create - they conceptually has no inputParDo, GroupByKey, CoGroupByKey, Combine and CountTextIO.WriteFriendly prices: charges are dependent on resource and minutes usage - totally a serverless process
Open source community: its SDK is always expanding with new features and new supported languages, aside from a very extensive list of I/O connectors mainly supported on Java and Python
Blazing fast: before even scaling resources, a simple and small pipeline can give some reasonable and fast results (one client had a pipeline that read up to 20 million records from MongoDB, transform and save the output into BigQuery in less than 20 minutes using just 2 workers)
Fan-out output: some connectors such as BigQuery allow pipelines to have dynamic destinations, allowing filtering to take place on write time
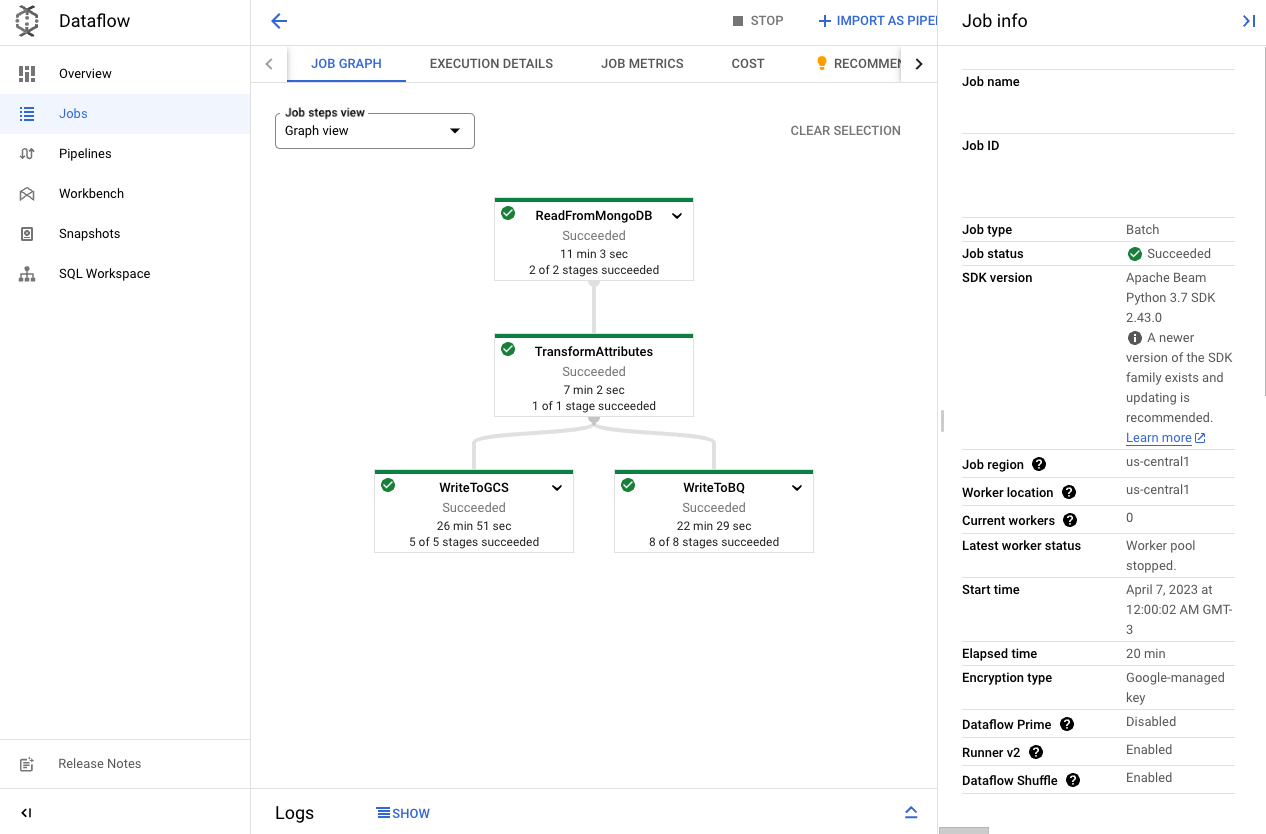
Developer friendly: through code semantics, Dataflow can translate code blocks into visual graphs, allowing developers to see which step is being executed in real-time and how long each phase took. As it can be seen below, a pipeline process that reads from MongoDB and saves the transformed output into GCS and BigQuery took an elapsed time of 20 minutes, whereas each phase has its specific total time and how many stages were performed
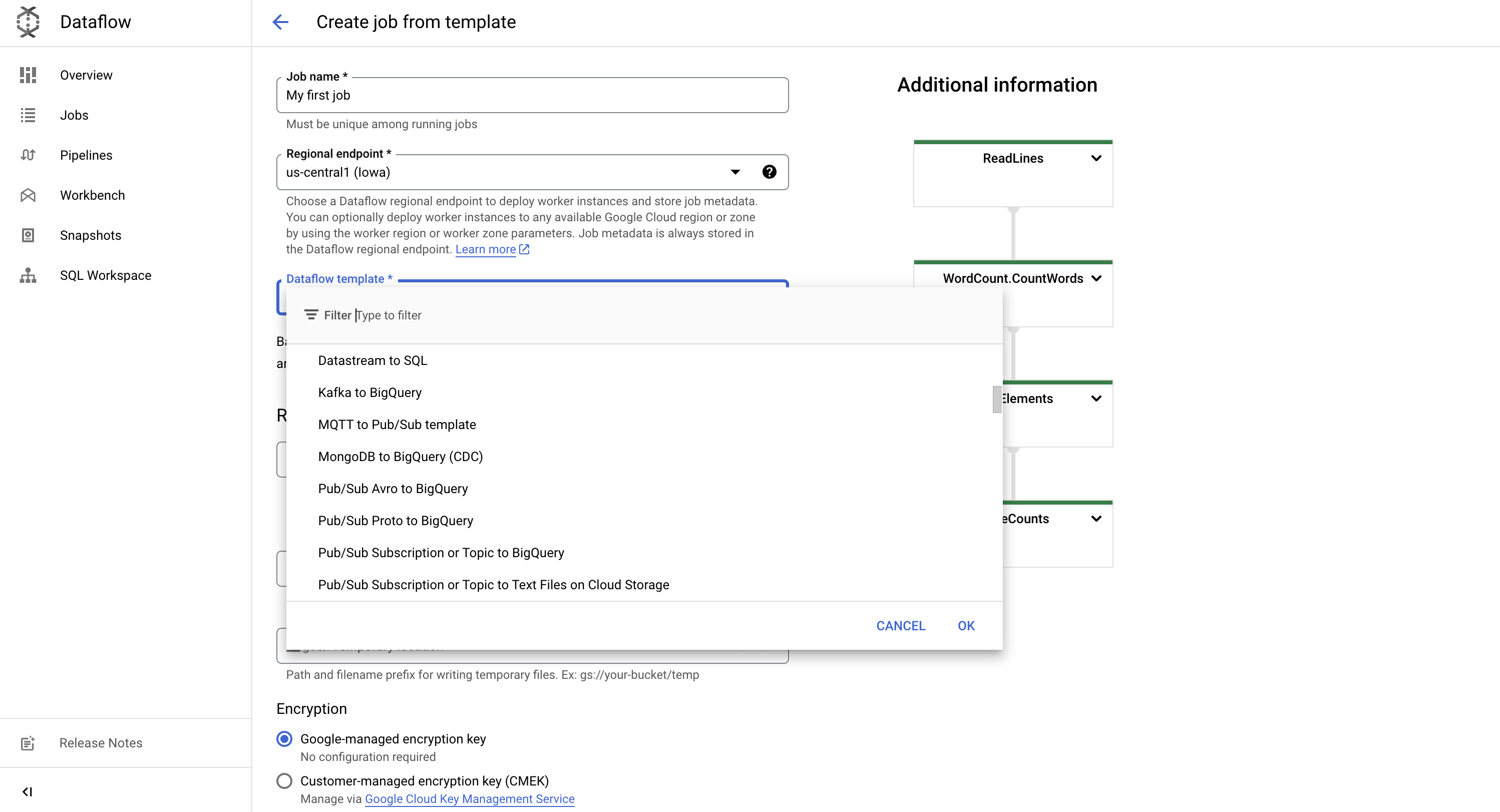
As for all Google Cloud services, Dataflow resources can be created either via CLI or through the console. In a nutshell, Dataflow allows users to create directly a job with pre-built (with multiple connectors, as it can be seen below) or custom templates:
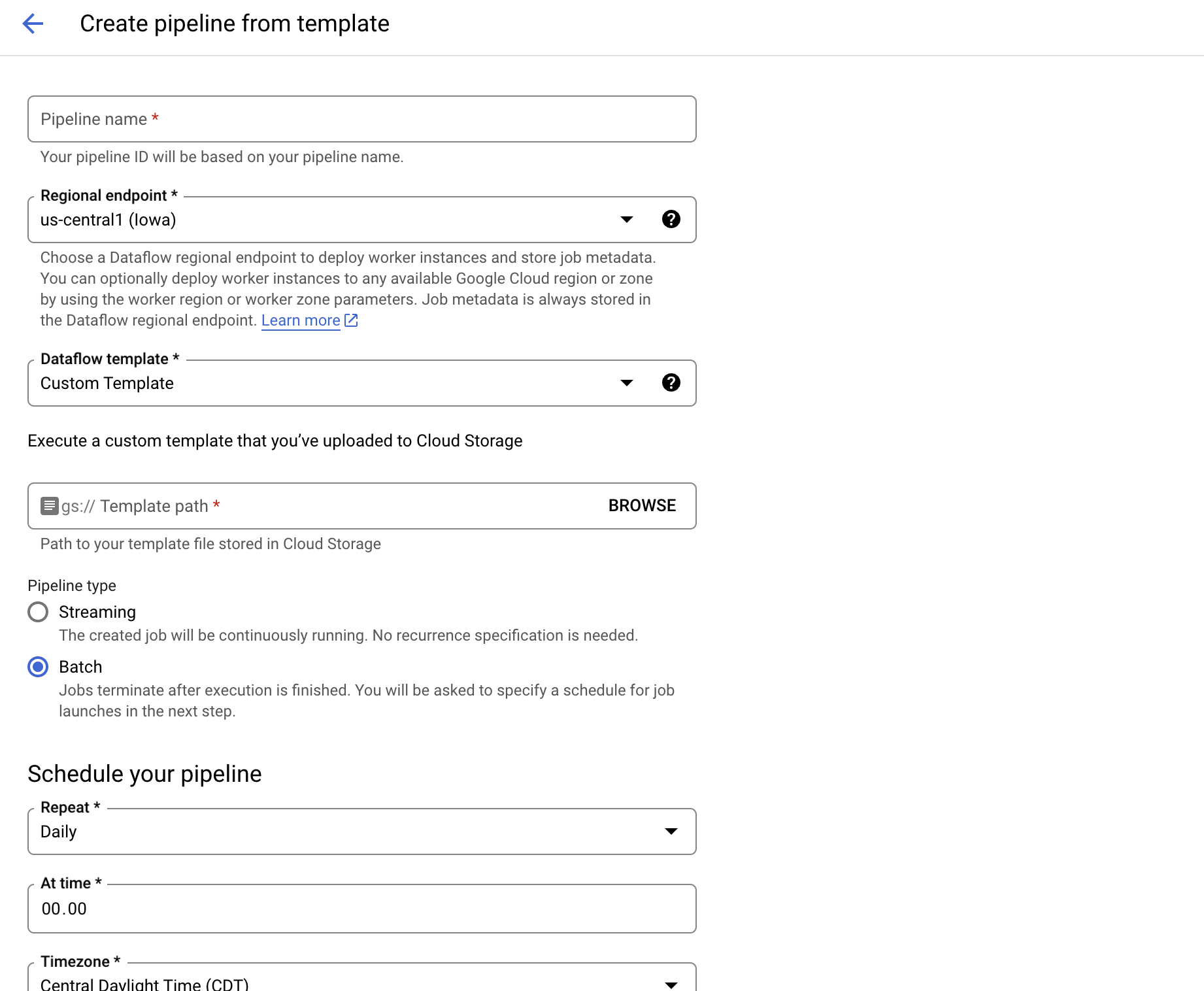
Creation can also happen for pipelines, which follows the same logic (i.e. you can select a pre-existent template or a custom one) but you need to select if the pipeline will be create batch (scheduled, as can be seen below) jobs or streaming jobs:
Dataflow has classic and flex templates, which allows users to establish a well-described document with dynamic metadata. This means that one flex template is able to accept different parameter values to create different pipelines with different results. A metadata file follows a JSON structure similar to the one below (multiple parameters can be defined):
{
"defaultEnvironment": {},
"image": "us-central1-docker.pkg.dev/<PROJECT>/<APP>/<JOB>:<TAG>",
"metadata": {
"description": "<DESCRIPTION>",
"name": "<NAME>",
"parameters": [
{
"helpText": "<HELP_TEXT>",
"isOptional": false,
"label": "<DATAFLOW_PARAMETER_LABEL>",
"name": "<DATAFLOW_PARAMETER_NAME>",
"paramType": "TEXT"
}
]
},
"sdkInfo": {
"language": "PYTHON"
}
}
Once the file is created, one can run the following CLI command in the terminal to create and store a flex template in GCS to make sure a dataflow job/pipeline can be created from it (make sure to authenticate to GCP with gcloud auth login and set the correct GCP project with gcloud config set project <PROJECT_NAME> before creating a flex template):
gcloud dataflow flex-template build gs://<GCS_BUCKET>/<TEMPLATE_FILE>.json --image us-central1-docker.pkg.dev/<GCP_PROJECT>/<APP>/<JOB>:<TAG> --sdk-language "PYTHON" --metadata-file "<TEMPLATE_LOCAL_FILE>.json"
For the record, the GCR docker image is not mandatory to exist prior to the template creation. However, when the template is schedule to start on Dataflow, the image needs to exist, so make sure to build and push to GCR and change the respective tag image (in case there's a release management in place) on the GCS template saved file.
Dataflow pipelines can also be created with the CLI after the template file creation. Google cloud beta plugin needs to be installed first. One example can be seen below for a project that extracts MongoDB records and save to BigQuery:
gcloud beta datapipelines pipeline create <APP> \
--pipeline-type=<BATCH/STREAMING> --region=<GCP_REGION> --project=<GCP_PROJECT> \
--max-workers=3 --num-workers=1 --schedule='0 0 * * *' --time-zone='US/Central' \
--temp-location='gs://<GCS_BUCKET>/temp' \
--template-file-gcs-location='gs://<GCP_BUCKET>/<TEMPLATE_FILE>.json' \
--worker-machine-type='n1-standard-1' \
--parameters=database_uri="<MONGO_DB_URI>",\
database_name="<MONGO_DB_NAME>",database_collection="<MONGO_DB_COLLECTION>",shards="<GCS_FILE_NUMBER_OF_SHARDS>",\
table_spec="<BQ_FULL_TABLE_SPEC>",\
gs_file_name="<FULL_GS_PATH_FILE_OUTPUT>",\
runner="DataflowRunner",project="<GCP_PROJECT>",job_name="<JOB_NAME>",\
temp_location="gs://<GCS_BUCKET>/temp",region="<GCP_REGION>"
Once that's created, the pipeline can be seen on the console through the Dataflow pipelines page:
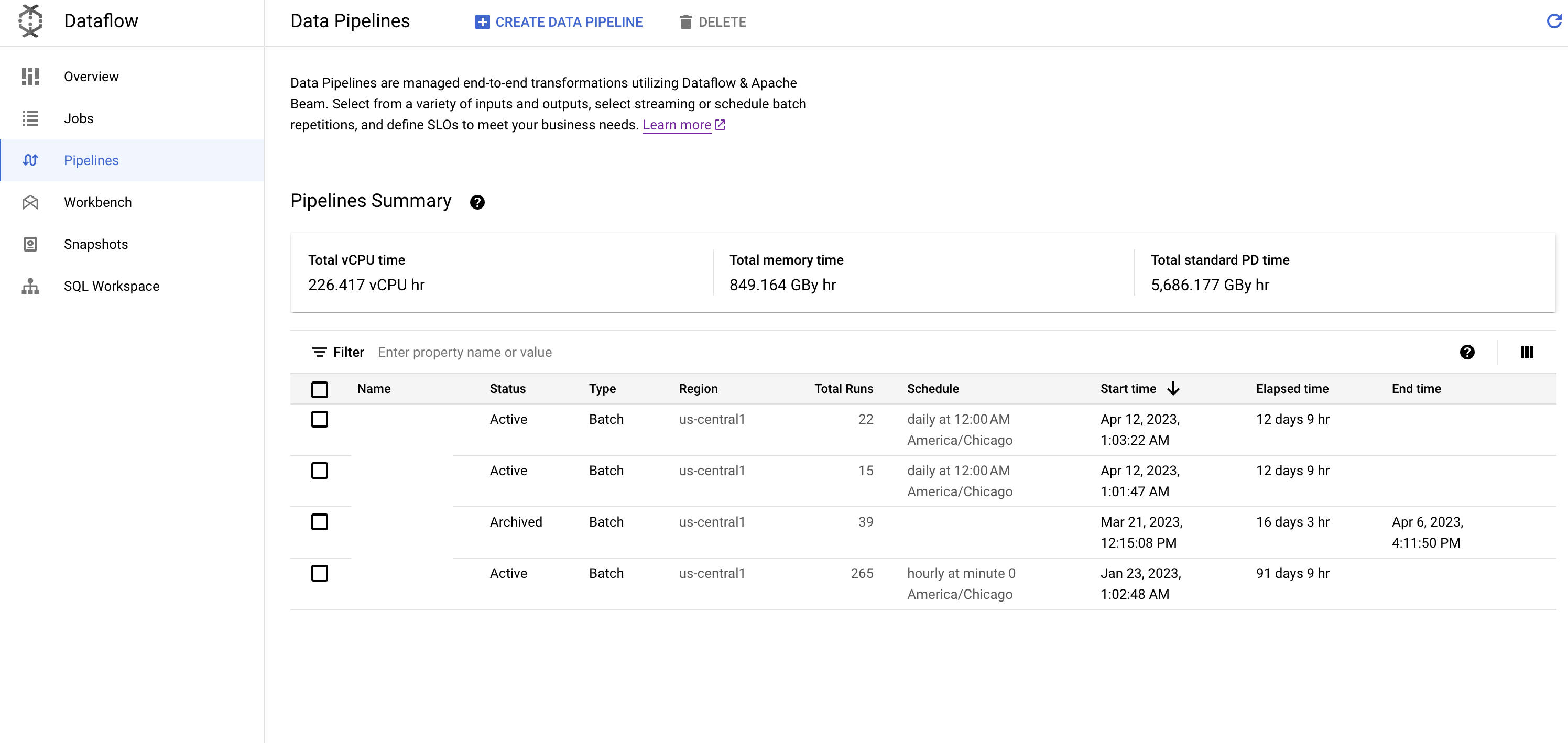
Inside each pipeline page, users can get a glimpse of jobs running at the moment, as well as status for the last N days and the previous jobs that executed:
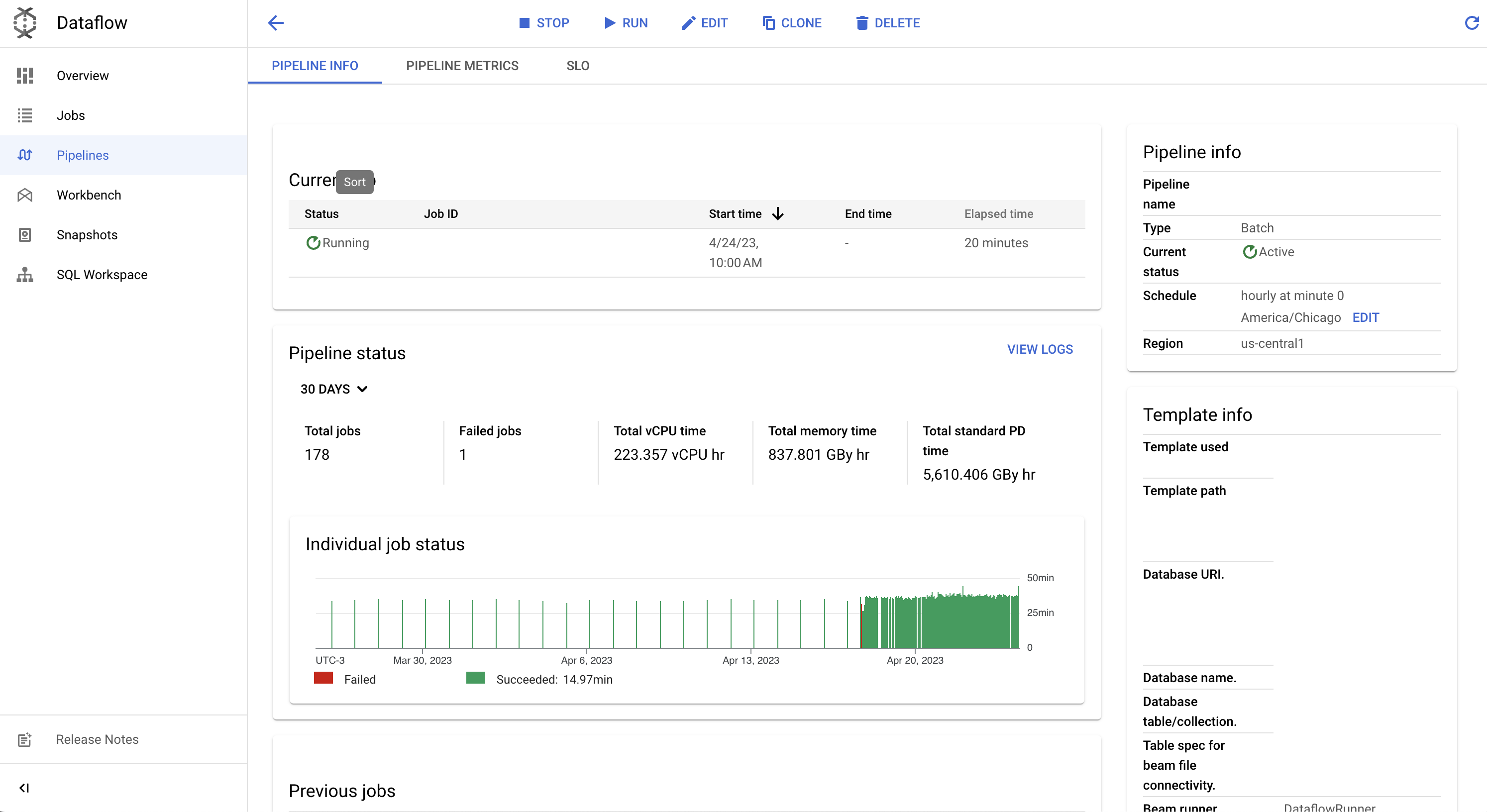
Even though Dataflow can be pretty much developer friendly and fast, there are some cons to be aware of:
Connecting jobs: some processes demand that jobs run in sequence. Natively speaking, Dataflow doesn't support that out-of-the-box, whereas developers need to either connect them through Log Sink (to fetch the end of a dataflow execution) with a cloud function or with a more robust orchestrator such as Google Composer (i.e. Apache AirFlow)
Non-native sources: for data fetching that happens outside of the native plugins/sources provided by the community (e.g. fetching data from Oracle NetSuite SQL REST API), some developers might face timeouts on their flex template pipelines. This means that either they reduce the quantity of data being fetched or they need to run a direct Dataflow job, which requires some extra crafting to make sure the batch job runs in a scheduled time.
Alerts: even though Google has a dashboard for pipeline status, which tells which jobs failed, how much vCPU/memory was consumed, it doesn't provide a native way to get notifications whenever a job fails. In order to get alerts to Slack or even Microsoft Teams, developers need to catch errors with Log Sink and send the information through REST webhooks, allowing their teamates to be aware of errors and allowing them to take action ASAP
We know that starting a big data architecture in the cloud can be dauting, but we are here to help to get it through with our years of expertise - we even have ready-to-go and compliant modules for the aforementioned challenges.
Contact us and we'll help you develop your data solution COMPLIANT in the cloud!
Share this article
Delivering the fastest path to security and compliance in the cloud.
© Copyright 2026 StarOps.
Proudly made in
Los Angeles, CA 🇺🇸
